聊聊如何搞定 eBay 商品数据爬取:尤其是让人头秃的类目层级问题
最近在做电商数据分析项目,老板给的任务是搞定 eBay 的全站商品数据和类目映射。说实话,写爬虫这么多年,eBay 的类目结构真让我头秃了一阵子。
很多刚上手的朋友可能觉得爬个商品列表页很简单,But,当你真正面对 eBay 这种有着几级深度的类目树时,你会发现“怎么判断是不是叶子节点”以及“什么时候该往下钻取”才是最大的坑。今天就把我的踩坑经验和解决思路分享出来,希望能帮大家省点头发。
一、为什么 eBay 的类目这么难搞?
不同于国内某些电商平台的直链结构,eBay 的类目录取逻辑有时候非常动态。最让人抓狂的是,它经常在同一个节点混搭“子分类”和“商品列表”。
如果你只是简单地抓取所有 <a> 标签,很容易陷入死循环,或者把一个本身包含商品的中间节点误判为叶子节点,导致数据缺失。更别提它现在对未登录用户的渲染逻辑和反爬策略也在不断升级。
二、核心痛点:如何精准判断叶子节点?
在处理类目树时,我们需要明确一个原则:只有叶子节点才包含具体的商品列表,非叶子节点的作用仅仅是导航。
1. 页面特征分析法
这是最简单直接的方法。通过观察页面 HTML 结构,我们可以得出以下判断逻辑:
eBay 深度类目树结构示例,展示从主类目到叶子节点的层级关系。
- 存在子类目列表块:如果页面上出现了类似于“Shop by Category”或者特定的子类目容器
div,那这绝对不是叶子节点。 - 存在商品列表块:反之,如果页面出现了
li标签包裹的商品卡片、价格信息,且页面底部的分页器(Pagination)是可用的,那么它大概率就是我们需要抓取数据的叶子节点。
2. URL 结构辅助判断
大部分情况下,eBay 的叶子类目 URL 会包含特定的关键字(比如 i.html 结尾),但这并不是绝对的,因为 SEO 友好的 URL 结构经常会变。所以这个方法只能作为辅助,不能作为唯一的 if 条件。
典型的 eBay 商品列表页,包含商品卡片和分页器。
三、Python 实现思路与伪代码
这里我们不直接贴现成的脚本(容易被封),主要分享实现逻辑。建议使用 requests 配合 lxml 或 BeautifulSoup,高阶玩家可以直接上 Playwright 或 Selenium 来应付动态渲染。
核心递归逻辑
我们需要维护一个队列或者直接使用 BFS(广度优先搜索)来遍历类目树。
# 伪代码示例
def parse_category(url):
html = fetch_page(url) # 这一步记得加 Headers 和代理
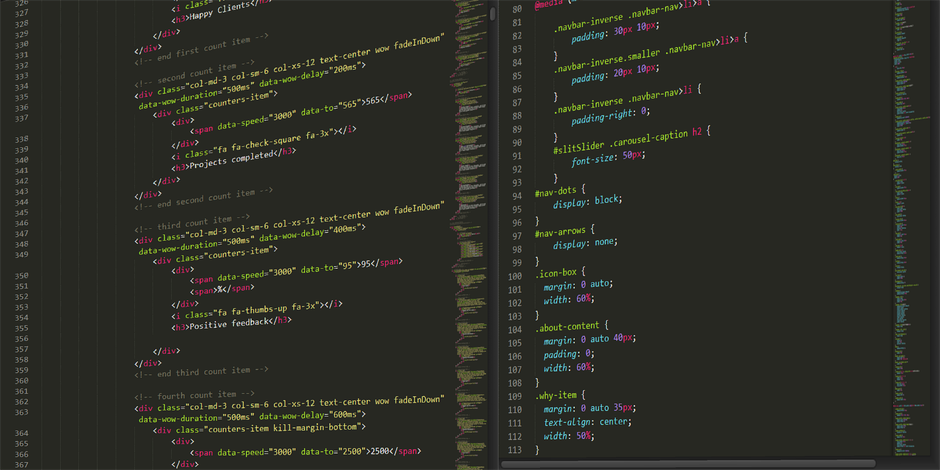
*使用 Python 实现类目树遍历的递归逻辑伪代码示例。*
# 1. 尝试寻找子分类链接
sub_categories = html.xpath('//div[@id="category-container"]//a/@href')
if sub_categories:
# 如果找到了子分类,说明这是父节点,继续递归或入队
for sub_url in sub_categories:
parse_category(sub_url)
else:
# 2. 如果没找到子分类,检查是否有商品列表
items = html.xpath('//li[contains(@class, "s-item")]
if items:
print(f"发现叶子节点: {url}, 开始抓取商品...")
save_items(items)
else:
print(f"空节点或反爬拦截: {url}")
状态保存很重要
爬全站数据最怕断电或程序崩溃。一定要把爬过的类目 URL 存入数据库或 Redis 缓存中,每次跑之前先查重,避免重复劳动。
四、必须要过的“反爬”关
eBay 遇到的反爬虫验证或风控拦截界面。
搞定了逻辑,还得过 eBay 的风控。eBay 的反爬主要针对高频请求和异常 User-Agent。
- IP 池是必备的:不要用单 IP 猛冲, residential proxies(住宅代理)的效果远好于数据中心 IP。
- 请求间隔随机化:设置
time.sleep(random.uniform(1, 3)),模拟人类浏览节奏。 - Cookies 池:如果你需要登录后才能看到的完整数据,维护一个有效的 Cookies 池至关重要。
- Headless Browser:如果遇到 Cloudflare 或者复杂的 JS 挑战,老老实实上 Playwright,虽然慢点,但通过率高。
五、总结
爬 eBay 商品数据的难点不在于单个页面的解析,而在于对庞大类目树的遍历策略。记住:
- 先看结构:通过 DOM 特征区分是导航页还是列表页。
- 后看数据:确信非空后再入库。
- 时刻防封:代理和随机间隔是保命符。
希望这篇思路分享能给正在做电商数据抓取的你一点方向。如果你有更好的去重或者并发策略,欢迎在评论区交流!
评论已关闭